
FlinkТў»СИђСИфтѕєтИЃт╝ЈуџёсђЂТюЅуіХТђЂуџёУ«Ау«ЌТАєТъХ№╝їт«ЃтЈ»С╗ЦтцёуљєТЌажЎљуџётњїТюЅжЎљуџёТЋ░ТЇ«ТхЂсђѓFlinkтјЪТюгУ«ЙУ«Ауџёт░▒Тў»тЈ»С╗ЦтюеТЅђТюЅуџёжђџтИИуџёжЏєуЙцуј»тбЃ№╝їтюетєЁтГўСИГУ┐ЏУАїС╗╗ТёЈУДёТеАуџёУ«Ау«Ќсђѓ
┬а
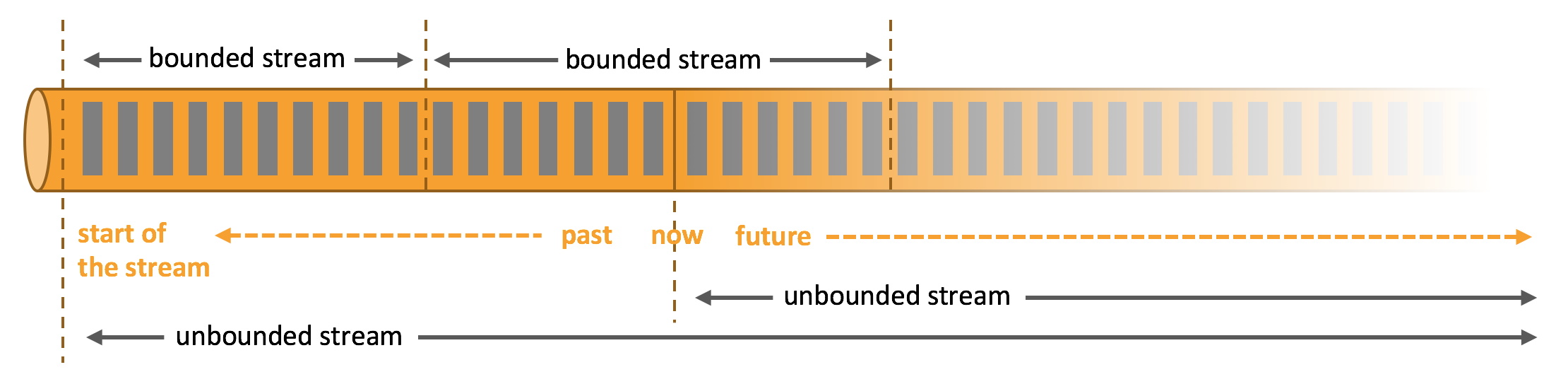
СИђсђЂтцёуљєТЌаУЙ╣уЋїуџётњїТюЅУЙ╣уЋїуџёТЋ░ТЇ«ТхЂ
С╗╗СйЋуДЇу▒╗уџёТЋ░ТЇ«жЃйТў»С╗ЦС║ІС╗ХТхЂуџётйбт╝ЈС║ДућЪуџё№╝їТ»ћтдѓС┐АућетЇАС║цТўЊсђЂС╝аТёЪтЎеТхІжЄЈсђЂТю║тЎеТЌЦт┐ЌТѕќУђЁућеТѕитюеуйЉуФЎТѕќУђЁуД╗тіет║ћућеСИіуџёС║цС║њуГЅ№╝їТЅђТюЅуџёУ┐ЎС║ЏТЋ░ТЇ«жЃйТў»С╗ЦТхЂуџётйбт╝ЈС║ДућЪуџёсђѓ
┬а
ТЋ░ТЇ«тЈ»С╗ЦС╗ЦТюЅУЙ╣уЋїуџёТѕќУђЁТЌаУЙ╣уЋїуџёТхЂуџётйбт╝ЈУбФтцёуљєсђѓ
┬а
┬а1сђЂТЌаУЙ╣уЋїуџёТЋ░ТЇ«ТхЂ
ТЌаУЙ╣уЋїуџёТЋ░ТЇ«ТхЂТюЅСИђСИфт╝ђтДІСйєТў»Т▓АТюЅт«џС╣ЅтЦйуџёу╗ЊТЮЪсђѓтЈфУдЂТЋ░ТЇ«тюеућЪС║Дт╣ХСИћтюеТЈљСЙЏ№╝їжѓБС╣ѕт«Ѓт░▒СИЇС╝џСИГТќГсђѓ
ТЌаУЙ╣уЋїуџёТЋ░ТЇ«ТхЂт┐ЁжА╗УбФТїЂу╗Гтю░тцёуљє№╝їС╣Ът░▒Тў»У»┤тюеflinkТјЦТћХтѕ░ТЋ░ТЇ«С╗Цтљјт┐ЁжА╗У┐ЁжђЪтцёуљєсђѓтЏаСИ║ТЋ░ТЇ«Тў»ТЌаУЙ╣уЋїуџё№╝їт╣ХСИћтюеС╗╗СйЋТЌХтђЎт«ЃжЃйСИЇТў»т«їТЋ┤уџё№╝їТЅђС╗Ц№╝їСИЇтЈ»УЃйуГЅтЙЁТЅђТюЅуџёТЋ░ТЇ«жЃйтѕ░УЙЙсђѓтцёуљєТЌаУЙ╣уЋїуџёТЋ░ТЇ«№╝їжђџтИИУдЂТ▒ѓС║ІС╗ХС╗ЦуЅ╣т«џуџёжА║т║ЈТјЦТћХ№╝їТ»ћтдѓС║ІС╗ХтЈЉућЪуџёжА║т║Ј№╝їС╗ЦСЙ┐тЈ»С╗Цт»╣у╗ЊТъюуџёт«їТЋ┤ТђДУ┐ЏУАїТјеуљєсђѓ
┬а
2сђЂТюЅУЙ╣уЋїуџёТЋ░ТЇ«ТхЂ
ТюЅУЙ╣уЋїуџёТЋ░ТЇ«ТхЂТюЅСИђСИфт«џС╣ЅтЦйуџёт╝ђтДІтњїу╗ЊТЮЪсђѓТюЅУЙ╣уЋїуџёТЋ░ТЇ«тЈ»С╗ЦтюеТјЦТћХтѕ░ТЅђТюЅуџёТЋ░ТЇ«С╗ЦтљјТЅЇт╝ђтДІТЅДУАїУ«Ау«ЌсђѓтюеТјЦТћХТюЅУЙ╣уЋїуџёТЋ░ТЇ«ТхЂТЌХТў»СИЇУдЂТ▒ѓТюЅт║Јуџё№╝їтЏаСИ║т«ЃТђ╗Тў»тЈ»С╗ЦУбФТјњт║ЈуџёсђѓТюЅУЙ╣уЋїуџёТЋ░ТЇ«ТхЂтцёуљєС╣ЪжђџтИИУбФуД░СИ║ТЅ╣тцёуљєсђѓ
┬а
┬а
┬а
Apache Flink ТЊЁжЋ┐тцёуљєТюЅУЙ╣уЋїуџётњїТЌаУЙ╣уЋїуџёТЋ░ТЇ«жЏєсђѓу▓ЙуА«уџёТЌХжЌ┤тњїуіХТђЂуџёТјДтѕХУ«ЕFlinkтЈ»С╗ЦУ┐љУАїТЌаУЙ╣уЋїТхЂуџёС╗╗ТёЈу▒╗тъІт║ћућеуеІт║ЈсђѓТюЅУЙ╣уЋїуџёТхЂућ▒тєЁжЃеуџёу«ЌТ│ЋтњїСИЊжЌеСИ║тЏ║т«џтцДт░ЈТЋ░ТЇ«жЏєУ«ЙУ«АуџёТЋ░ТЇ«у╗ЊТъёТЮЦтцёуљє№╝їУ┐ЎуДЇУ«ЙУ«АСИ║С╝ўуДђуџёТђДУЃйтЂџтЄ║ТЮЦУ«ЕТГЦсђѓ
┬а
СйатЈ»С╗ЦТјбу┤бтЪ║С║јFlinkуџёућеСЙІТЮЦУ»┤ТюЇУЄфти▒сђѓ
┬а
┬а
С║їсђЂтюеС╗╗ТёЈтю░Тќ╣жЃеуй▓т║ћуће
Apache FlinkТў»тѕєтИЃт╝Јуџёу│╗у╗Ъ№╝їт╣ХСИћжюђУдЂУ«Ау«ЌУЄфУеђТЮЦТЅДУАїт║ћућесђѓFlinkСИјтИИућеуџёжЏєуЙцу«Ауљєу│╗у╗ЪтцЕуёХуџётЁ╝т«╣№╝їТ»ћтдѓHadoop YARN№╝ї Apache Mesos№╝ї С╗ЦтЈіKubernetes№╝їСйєТў»т«ЃС╣ЪтЈ»С╗ЦСйюСИ║СИђСИфуІгуФІуџёжЏєуЙцУ┐љУАїсђѓ
┬а
FlinkУ«ЙУ«АТюгУ║Фт░▒Сй┐тЁХУЃйтцЪСИјтЅЇжЮбТЈљтѕ░уџёУхёТ║љу«АуљєтЎежЮътИИтЦйуџётиЦСйюсђѓУ┐ЎТў»жђџУ┐ЄУхёТ║љу«АуљєуЅ╣т«џуџёжЃеуй▓жЃеуй▓ТеАт╝Јт«ъуј░уџё№╝їУ┐ЎуДЇТеАт╝ЈтЁЂУ«ИFlinkС╗ЦтЁХу«АућеуџёТќ╣т╝ЈСИјТ»ЈСИђСИфУхёТ║љу«АуљєтЎеС║цС║њсђѓ
┬а
тйЊжЃеуй▓Flinkт║ћућеуџёТЌХтђЎ№╝їFlinkТа╣ТЇ«т║ћућежЁЇуй«уџёт╣ХтЈЉУЄфтіеуџёУ»єтѕФжюђУдЂуџёУхёТ║љ№╝їт╣ХСИћтљЉУхёТ║љу«АуљєтЎеућ│У»иУхёТ║љсђѓтЂЄтдѓТЪљСИфт«╣тЎетц▒У┤Ц№╝їжѓБС╣ѕFlinkтѕЎС╝џУ»иТ▒ѓТќ░уџёУхёТ║љТЮЦТЏ┐С╗Бтц▒У┤Цуџёт«╣тЎесђѓТЅђТюЅуџёТЈљС║цТѕќУђЁТјДтѕХт║ћућежЃйТў»жђџУ┐ЄRESTУ░ЃућесђѓУ┐Ўу«ђтїќС║єFlinkтюетцџуДЇуј»тбЃСИГуџёжЏєТѕљсђѓ
┬а
СИЅсђЂУ┐љУАїС╗╗ТёЈУДёТеАуџёт║ћуће
FlinkТюгУ║ФУ«ЙУ«Ат░▒Тў»УдЂУ┐љУАїС╗╗ТёЈУДёТеАуџёТюЅуіХТђЂуџёТхЂт╝Јт║ћућесђѓт║ћућеТў»т╣ХУАїуџёУ┐љУАїТЋ░тЇЃСИфС╗╗тіА№╝їУ┐ЎС║ЏС╗╗тіАТў»тѕєтИЃт╝Јуџёт╣ХСИћтюежЏєуЙцСИГт╣ХтЈЉтю░ТЅДУАїсђѓтЏаТГц№╝їСИђСИфт║ћућетЄаС╣јУЃйтцЪСй┐ућеТЌажЎљТЋ░жЄЈуџёCPUсђЂтєЁтГў№╝ѕmain memory№╝ЅсђЂуБЂуЏўС╗ЦтЈіуйЉу╗юIOсђѓТГцтцќ№╝їFlinkС╣ЪтЈ»С╗ЦтЙѕУй╗ТўЊуџёу╗┤ТіцжЮътИИтцДжЄЈуџёт║ћућеуіХТђЂсђѓт«Ѓуџёт╝ѓТГЦтњїтбъжЄЈуџёТБђТЪЦуѓ╣№╝ѕcheckpointing№╝ЅтюеС┐ЮУ»ЂС╗ЁС╗ЁСИђТгА№╝ѕexactly-once№╝ЅуіХТђЂСИђУЄ┤ТђДуџётљїТЌХ№╝їС╣ЪуА«С┐ЮС║єт»╣У┐љУАїт╗ХУ┐ЪТюђт░Јуџётй▒тЊЇсђѓ
┬а
ТюЅућеТѕиСИіТіЦС║єС╗ќС╗гућЪС║Дуј»тбЃСИГуџёС╗цС║║тЇ░У▒АТи▒тѕ╗уџёFlinkт║ћућеуеІт║ЈуџётцДУДёТеАТЋ░жЄЈ№╝їТ»ћтдѓ№╝џ
┬а
- Т»ЈтцЕУ┐љУАїтЄаСИЄС║┐уџёС║ІС╗Х№╝Џ
- С┐ЮтГўС║єтЄаTBуџёуіХТђЂС┐АТЂ»№╝Џ
- тљїТЌХУ┐љУАїС║єТѕљтЇЃСИіСИЄуџётєЁТаИ№╝Џ
┬а
тЏЏсђЂтѕЕућетєЁтГўТђДУЃй
┬а
ТюЅуіХТђЂуџёFlinkт║ћућеТў»тЁЁтѕєтѕЕућеТюгтю░уџёуіХТђЂУ«┐жЌ«сђѓС╗╗тіАуџёуіХТђЂТђ╗Тў»С┐ЮтГўтюетєЁтГўСИГуџё№╝їтдѓТъюуіХТђЂуџётцДт░ЈУХЁУ┐ЄС║єтЈ»ућеуџётєЁтГў№╝їтѕЎС╗ЦСИђСИфтЈ»жФўТЋѕУ«┐жЌ«уџёТЋ░ТЇ«у╗ЊТъётГўтѓетюеуБЂуЏўСИісђѓтЏаТГц№╝їС╗╗тіАжђџУ┐ЄУ«┐жЌ«Тюгтю░уџё№╝ѕжђџтИИТў»тєЁтГўСИГуџё№╝ЅуіХТђЂС┐АТЂ»ТЮЦТЅДУАїУ«Ау«Ќ№╝їУ┐ЎСй┐тЙЌУ«Ау«Ќт╗ХТЌХжЮътИИСйјсђѓFlinkжђџУ┐Єт╝ѓТГЦуџёС┐ЮтГўТюгтю░уіХТђЂтѕ░уе│т«џуџётГўтѓеСИГТЮЦжў▓ТГбтц▒У┤ЦуџёТЃЁтєхтЈЉућЪ№╝їжђџУ┐ЄУ┐ЎуДЇТќ╣т╝ЈТЮЦС┐ЮУ»Ђexactly-onceсђѓ
┬а
┬а
тЈѓУђЃТќЄТАБ№╝џhttp://flink.apache.org/flink-architecture.html
┬а
Flinkу«ђС╗ІУ»иТЪЦуюІ№╝џApache Flink ТдѓУДѕ - ТюЅуіХТђЂуџёТхЂт╝ЈУ«Ау«Ќ
┬а
┬а
┬аТЅЊСИфт╣┐тЉі№╝їСИфС║║уйЉуФЎ№╝їТЪЦуюІтЁеуФЎуџёТюђТќ░уЃГуѓ╣№╝їУ»иУ«┐жЌ«№╝џжбєУѕфТдютЇЋ
┬а
┬а
┬а



уЏИтЁ│ТјеУЇљ
FlinkТіђТю»жбёуаћ№╝їтљёУ«Ау«Ќт╝ЋТЊјт»╣Т»ћсђѓflinkТъХТъё
flinkТъХТъёУ«ЙУ«АСИјСИЊСИџТю»У»Г
FlinkТъХТъётјЪуљєсђЂFlinkт║ћућетю║ТЎ»сђЂFlinkуЅ╣уѓ╣С╝ўті┐сђЂFlinkтѕєтИЃт╝ЈжЏєуЙцС╝ЂСИџу║ДжЃеуй▓сђЂFlinkС╗╗тіАТЈљС║цсђЂжФўтЈ»ућесђЂт╣ХУАїт║дУ«Йуй«тЈітЈѓТЋ░жЁЇуй«сђЂтИИућеAPIсђЂFlinkуфЌтЈБсђЂFlinkуіХТђЂсђЂFlinkTableсђЂFlinkSQLсђЂFlinkтцЇТЮѓТЌХжЌ┤уГЅСИђу│╗тѕЌFlinkуЃГуѓ╣...
FlinkТъХТъёУ«ЙУ«АтЅќТъљ,ТхЂStateуџёУ«▓УДБтњїу╗ЃС╣ат«ъТѕў
1 Flink С╗╗тіАТЈљС║цТхЂуеІ TaskManagerТў»СИђСИфуІгуФІуџёjvmУ┐ЏуеІсђѓ Т»ЈСИфtask slotУАеуц║TaskManagerТІЦТюЅУхёТ║љуџёСИђСИфтЏ║т«џтцДт░ЈуџётГљжЏєсђѓтЂЄтдѓСИђСИфTaskManagerТюЅСИЅСИфslot,жѓБС╣ѕт«ЃС╝џт░єтЁХу«АуљєуџётєЁтГўтѕєТѕљСИЅС╗йу╗ЎтљёСИфslotсђѓ slotт░▒Тў»У┐љУАїтюе...
уггС║їуФа FlinkТъХТъёСйЊу│╗ 01.FlinkСИГжЄЇУдЂУДњУЅ▓ 02.ТЌауЋїТЋ░ТЇ«ТхЂСИјТюЅуЋїТЋ░ТЇ«ТхЂ 03.FlinkТЋ░ТЇ«ТхЂу╝ќуеІТеАтъІ 04.LibrariesТћ»ТїЂ уггСИЅуФа FlinkжЏєуЙцТљГт╗║ 01.уј»тбЃтЄєтцЄтиЦСйю 02.localТеАт╝Ј 03.StandaloneжЏєуЙцТеАт╝Ј 04.Standalone-HAжЏєуЙц...
уггС║їуФа FlinkТъХТъёСйЊу│╗ 8 уггСИЅуФа FlinkжЏєуЙцТљГт╗║ 12 уггтЏЏуФа DataSetт╝ђтЈЉ 48 уггС║ћуФа DataStreamт╝ђтЈЉ 111 уггтЁГуФа Window 157 уггСИЃуФа EventTime-Watermark(жџЙуѓ╣) 175 уггтЁФуФа FlinkуџёуіХТђЂу«Ауљє 200 уггС╣ЮуФа Flinkуџёт«╣жћЎ 226 ...
ApacheFlinkУЃйтцЪтЪ║С║јтљїСИђСИфFlinkУ┐љУАїТЌХ№╝їТЈљСЙЏТћ»ТїЂТхЂтцёуљєтњїТЅ╣тцёуљєСИцуДЇу▒╗тъІт║ћућеуџётіЪУЃйсђѓуј░ТюЅуџёт╝ђТ║љУ«Ау«ЌТќ╣ТАѕ№╝їС╝џТііТхЂтцёуљєтњїТЅ╣тцёуљєСйюСИ║СИцуДЇСИЇтљїуџёт║ћућеу▒╗тъІ№╝їтЏаСИ║т«ЃС╗гТЅђТЈљСЙЏуџёSLA№╝ѕService-Level-Aggreement№╝ЅТў»т«їтЁеСИЇ...
ТюгтЦЌТАѕСЙІТў»т«їтЁетЪ║С║јуюЪт«ъуџёС║ДтЊЂУ┐ЏУАїт╝ђтЈЉтњїУ«▓УДБуџё№╝їтљїТЌХт»╣ТъХТъёУ┐ЏУАїтЁежЮбуџётЇЄу║Д№╝їжЄЄућеС║єтЁеТќ░уџёFlinkТъХТъё+Node.js+Vue.jsуГЅ№╝їт«їтЁеугдтљѕуЏ«тЅЇС╝ЂСИџу║ДуџёСй┐ућеТаЄтЄєсђѓт»╣С║јТюгтЦЌУ»ЙуеІтюеС╝ЂСИџу║Дт║ћућеуџёжЌ«жбў№╝їтЈ»С╗ЦТЈљСЙЏтЁежЮбуџёТїЄт»╝сђѓ ...
угг1 уФаFlink ТъХТъёСИјжЏєуЙцт«ЅУБЁ...............................................................................................................................- 1 - 1. 1 Flink у«ђС╗І.............................
тцДТЋ░ТЇ«т«ъТЌХУ«Ау«ЌFlink SQLТъХТъёС╗Іу╗Ї.pptx
РћюРћђ01-тцДТЋ░ТЇ«С╣ІFlinkТАєТъХ - Java.doc РћюРћђ01-тцДТЋ░ТЇ«С╣ІFlinkТАєТъХ - Scala.doc (2)\2.УхёТќЎ№╝ЏуЏ«тйЋСИГТќЄС╗ХТЋ░:0СИф (3)\3.С╗БуаЂ№╝ЏуЏ«тйЋСИГТќЄС╗ХТЋ░:2СИф РћюРћђflink-java-code.zip РћюРћђflink-scala-code.zip (4)\4.УДєжбЉ№╝ЏуЏ«тйЋСИГТќЄ...
flinkТіђТю»тѕєТъљ№╝їтюеУ┐ЎжЄї№╝їТѕЉС╗гУДБжЄіFlinkТъХТъёуџёжЄЇУдЂТќ╣жЮб№╝їApache FlinkТў»С╗ђС╣ѕ №╝їApache FlinkТюЅтЊфС║ЏТќ╣жЮбуџёуЅ╣ТђД№╝їт»╣flinkуџётЁежЮбтЅќТъљ
сђљFlinkу»Є04сђЉFlinkУ┐љУАїТЌХТъХТъё1
FlinkТіђТю»ТъХТъётЈіТюђСй│т«ъУих.pptx
СйюСИ║Тќ░СИђС╗Буџёт╝ђТ║љТхЂтцёуљєтЎе№╝їFlinkТў»С╝ЌтцџтцДТЋ░ТЇ«тцёуљєТАєТъХСИГСИђжбЌтєЅтєЅтЇЄУхиуџёТќ░ТўЪсђѓт«ЃС╗ЦтљїСИђуДЇТіђТю»Тћ»ТїЂТхЂтцёуљєтњїТЅ╣тцёуљє...- ТхЂтцёуљєТъХТъёуЏИУЙЃС║јТЅ╣тцёуљєТъХТъёуџёС╝ўті┐ - FlinkСИГуџёТЌХжЌ┤Тдѓт┐х - FlinkуџёТБђТЪЦуѓ╣Тю║тѕХ - FlinkуџёТђДУЃйС╝ўті┐
уггтЏЏуФа FlinkУ┐љУАїТъХТъё уггС║ћуФа FlinkТхЂтцёуљєAPI уггтЁГуФа FlinkСИГуџёWindow уггСИЃуФа ТЌХжЌ┤У»ГС╣ЅСИјWatermark уггтЁФуФа ProcessFunction API№╝ѕт║Ћт▒ѓAPI№╝Ѕ уггС╣ЮуФа уіХТђЂу╝ќуеІСИјт«╣жћЎТю║тѕХ уггтЇЂуФа Table API СИј SQL
С╗Ё1т╣┤GitHub StarТЋ░у┐╗тђЇ№╝їApache Flink тЂџС║єС╗ђС╣ѕ№╝Ъ 4 LyftтЪ║С║јApache FlinkуџётцДУДёТеАтЄєт«ъТЌХТЋ░ТЇ«тѕєТъљт╣│тЈ░ 15 ТЌЦтЮЄтцёуљєСИЄС║┐ТЋ░ТЇ«№╝ЂApache Flinkтюет┐ФТЅІуџёт║ћућет«ъУихСИјТіђТю»Т╝ћУ┐ЏС╣ІУи» 26 bilibiliт«ъТЌХт╣│тЈ░уџёТъХТъёСИјт«ъУих 47 уЙјтЏб...