
Apache Flink 是一个支持有状态的计算的框架,它可以用来处理有边界的数据流和无边界的数据流。Flink 提供了多种不同抽象级别的API,并且提供对于常见的用例提供专用的函数库。
一、为流式应用构建好的模块
可以构建的并且被流式处理框架执行的应用类型是由框架是怎么来控制流、状态和事件来决定的。下面,我们将描述这些流式处理应用的构建块(building blocks),并且解释flink是怎么处理他们的。
1、流(Streams)
很明显,流是数据流处理的最基本的方面。然而,流的不同特性会影响这个流可以或者应该怎么样来处理。Flink是一个全能的处理框架,它可以处理任何种类的流。
- 有边界的和无边界的流:流可能是有边界的或者无边界的,比如固定大小的数据集。Flink具有专门特性来处理无边届的流,但是也有专门来处理有边界的流的操作。
- 实时的和历史的(Recorded)流:所有的数据是以流的形式产生的。有两种方式处理数据:当它产生的时候实时的处理,或者把他持久化到一个存储系统,比如文件系统或对象存储,稍后再处理它。Flink应用可以处理这两种流。
2、状态(State)
每一个有意义的流式应用都是有状态的,除非那些单独转换的事件不需要状态。任何一个运行基本的业务逻辑的应用都需要记住事件或者中间结果以在后续的某一个时间点访问他们,比如下一个事件被接收到或者某一个特定的时间段。
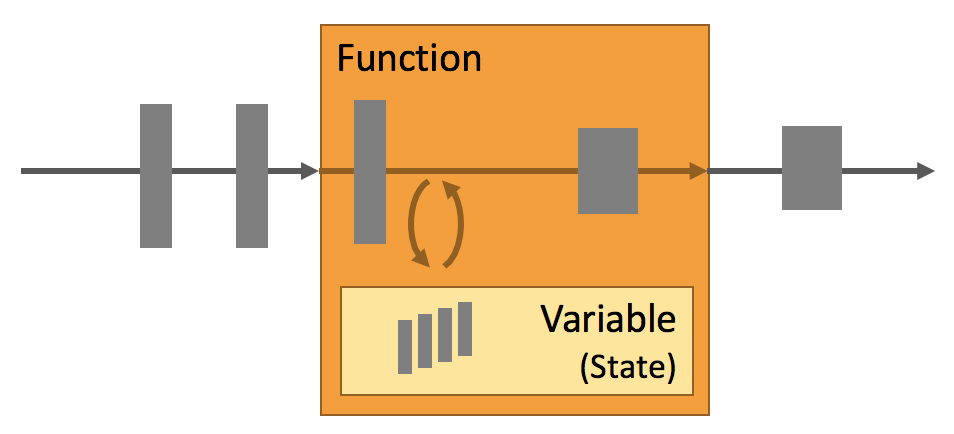
应用状态是Flink的最优秀的特性。下面你可以看到Flink关于状态处理的所有特性:
- 多状态基元(Primitives):Flink为不同的数据结构都提供了状态基元(primitives),比如原子的值、list或者map。开发者可以基于函数的访问模型选择最高效的状态基元。
- 可插入式的状态后端(Pluggable State Backends):应用的状态是被可插入式的状态后端管理和做检查点的。Flink的特点是不同的状态后端都存储在内存或者RocksDB,RocksDB是一个非常高效的基于磁盘的内嵌数据存储。常见的状态后端也是可插入式的。
- exactly-once状态一致性:Flink的检查点和回复算法保证了在万一失败时应用状态的一致性。因此,失败可以非常容易的处理掉并且不影响应用的正确性。
- 非常大的的状态信息:FLink可以保存几TB的应用状态信息,因为它是异步的并且增量的检查点算法。
- 可伸缩的应用:Flink可以重新分配状态到更多或者更少的工作节点,因此它支持有状态的应用的伸缩。
3、Time
时间是流式应用的另一个重要的组成部分。大部分的事件流有其固有的时间语义,因为每一个时间都是在特定的时间点生产的。此外,非常多常见的流式计算都是基于时间的,比如窗口聚合、会话流程(sessionization)、模式检测以及基于时间的关联。流式处理的一个重要方面就是应用应该怎么来控制(measures)时间,比如事件时间和处理时间的不同。
Flink提供了丰富的时间相关的特性:
- Event-time Mode:使用event时间与依赖处理流的应用基于event的时间戳来计算结果。因此,无论是处理记录好的event或者实时的event,事件时间处理允许精确的和保持一致性的结果;
- Watermark Support:Flink在event-time应用中使用水印(wartermark)来处理(reason)时间。对于权衡延时和结果的计算来说,watermark是一个灵活的机制。
- Late Data Handling:当使用watermark并且以event-time模式处理stream的时候,很有可能在一些相关的event到达之前,计算已经完成了。这些event被称作迟到的event。Flink提供了多种特性来处理late event,比如通过侧输出重新路由他们( rerouting them via side outputs),然后更新先前完成的结果。
- Processing-time Mode:除了event-time模式之外,Flink也支持处理时间的语义,它是通过正在执行的机器的时钟时间来触发计算的执行的。处理时间模式适用于对于可以忍受近似结果的有需求的低延时的应用。
二、分层的API
Flink提供了三层API,每层API针对不同的用例,在简洁性和表达性之间提供了不同的权衡。
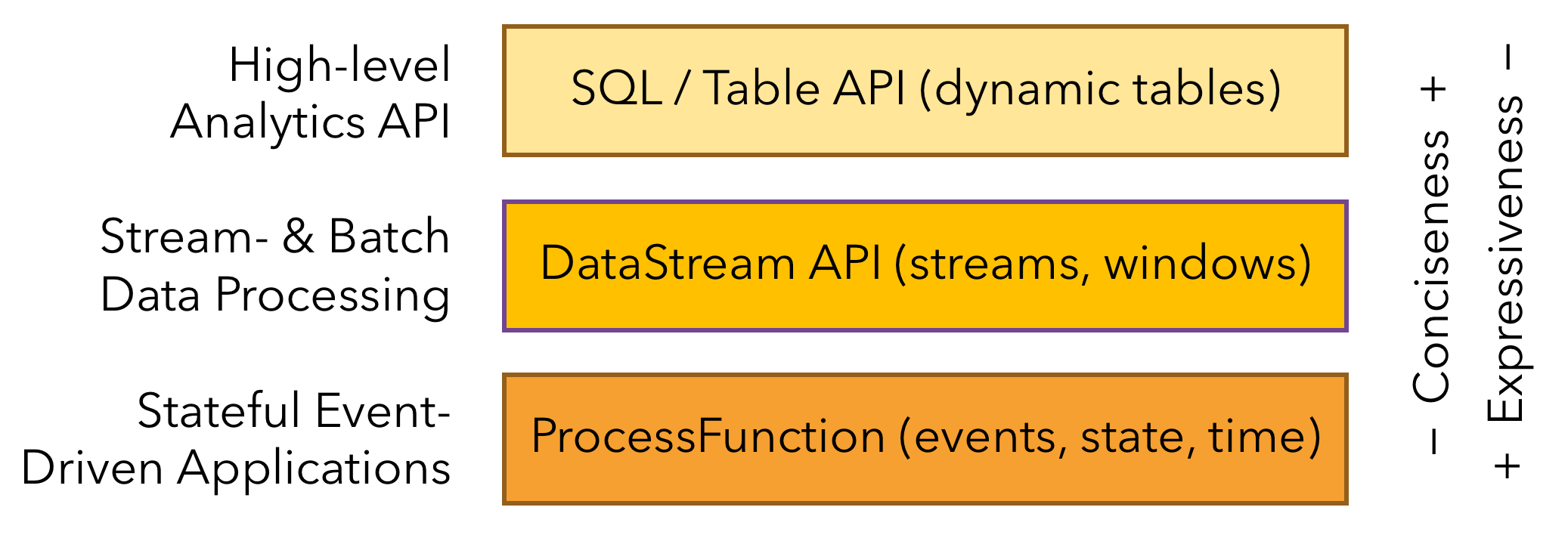
下面我们简要的介绍每一个API,讨论他的应用程序并且展示代码示例。
1、处理函数(ProcessFunctions)
处理函数 是Flink提供的最具有表现力的接口。Flink 提供的ProcessFuntion是用来处理来自于一个或者两个输入流或者一段时间窗内的聚合的独立event。ProcessFunction提供了对时间和状态的细粒度控制。一个ProcessFunction可以任意的修改它的状态,并且也可以注册定时器在将来触发一个回调函数。因此,ProcessFunction可以根据需要为有很多有状态的事件驱动的应用实现复杂的单事件业务逻辑。
下面的例子展示了用来操作KeyedStream并且可以匹配START 和 END 的KeyedProcessFunction,这个函数会记录他的状态的时间戳,并且在四小时之内注册一个定时器。如果在定时器执行之前接收到END event,这个函数会计算END和START这段区间,清空状态并且返回值。另外,这个定时器仅仅触发来清空状态。
/**
* Matches keyed START and END events and computes the difference between
* both elements' timestamps. The first String field is the key attribute,
* the second String attribute marks START and END events.
*/
public static class StartEndDuration
extends KeyedProcessFunction<String, Tuple2<String, String>, Tuple2<String, Long>> {
private ValueState<Long> startTime;
@Override
public void open(Configuration conf) {
// obtain state handle
startTime = getRuntimeContext()
.getState(new ValueStateDescriptor<Long>("startTime", Long.class));
}
/** Called for each processed event. */
@Override
public void processElement(
Tuple2<String, String> in,
Context ctx,
Collector<Tuple2<String, Long>> out) throws Exception {
switch (in.f1) {
case "START":
// set the start time if we receive a start event.
startTime.update(ctx.timestamp());
// register a timer in four hours from the start event.
ctx.timerService()
.registerEventTimeTimer(ctx.timestamp() + 4 * 60 * 60 * 1000);
break;
case "END":
// emit the duration between start and end event
Long sTime = startTime.value();
if (sTime != null) {
out.collect(Tuple2.of(in.f0, ctx.timestamp() - sTime));
// clear the state
startTime.clear();
}
default:
// do nothing
}
}
/** Called when a timer fires. */
@Override
public void onTimer(
long timestamp,
OnTimerContext ctx,
Collector<Tuple2<String, Long>> out) {
// Timeout interval exceeded. Cleaning up the state.
startTime.clear();
}
}
这个例子说明了KeyedProcessFunction的表现力,但是也强调了它是一个相当冗长的接口。
2、DataStream API
DataStream API为很多常用的流式计算操作提供了基元,比如窗口(windowing)、记录的转换(record-at-a-time transformations),并且通过查询外部存储来丰富event。DataStream API对于Java和Scala都是可用的,并且它是基于函数的,比如map()、reduce()以及aggregate()。函数可以通过扩展接口或者Java或Scala的lambda表达式来定义。
下例展示了如果对点击流进行会话处理,并且计算每个会话的点击次数。
DataStream<Click> clicks = ...
DataStream<Tuple2<String, Long>> result = clicks
// project clicks to userId and add a 1 for counting
.map(
// define function by implementing the MapFunction interface.
new MapFunction<Click, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(Click click) {
return Tuple2.of(click.userId, 1L);
}
})
// key by userId (field 0)
.keyBy(0)
// define session window with 30 minute gap
.window(EventTimeSessionWindows.withGap(Time.minutes(30L)))
// count clicks per session. Define function as lambda function.
.reduce((a, b) -> Tuple2.of(a.f0, a.f1 + b.f1));
3、SQL & Table API
Flink提供了两种关系型的API,Table API 和 SQL 。对于批处理和流处理来说,这两种API是一致的,比如无边界的实时的流或者有边界的记录好的流产生相同的结果,都是使用相同的语义来执行查询。Table API 和 SQL 使用 Apache Calcite 进行转换、校验和查询优化。他们可以无缝的与DataStream和DataSet API结合,并且支持用户定义的分层级的(scalar)、聚合的、表值(table-value)类型的函数。
Flink的关系型API目的是为了简化数据分析、数据流水(data pipeline)以及ETL应用的定义。
下面的例子展示了会话处理点击流并且计算每个会话的点击数量的SQL 查询语句。这是与DataStream API例子中相同的场景。
SELECT userId, COUNT(*) FROM clicks GROUP BY SESSION(clicktime, INTERVAL '30' MINUTE), userId
三、函数库(Libraries)
对于通常的数据处理用例,FLink提供了几种函数库。这些函数库通常嵌入在API中,而不是完全自包含的。因此,他们可以在API的所有特性中获益,并且与其他函数库集成。
- 复杂事件处理(CEP):对于事件流来说,模式检测是一个非常常见的用例。Flink’s CEP library provides an API to specify patterns of events (think of regular expressions or state machines). The CEP library is integrated with Flink’s DataStream API, such that patterns are evaluated on DataStreams. Applications for the CEP library include network intrusion detection, business process monitoring, and fraud detection.
- DataSet API:The DataSet API is Flink’s core API for batch processing applications. The primitives of the DataSet API include map, reduce, (outer) join, co-group, and iterate. All operations are backed by algorithms and data structures that operate on serialized data in memory and spill to disk if the data size exceed the memory budget. The data processing algorithms of Flink’s DataSet API are inspired by traditional database operators, such as hybrid hash-join or external merge-sort.
- Gelly:Gelly is a library for scalable graph processing and analysis. Gelly is implemented on top of and integrated with the DataSet API. Hence, it benefits from its scalable and robust operators. Gelly features built-in algorithms, such as label propagation, triangle enumeration, and page rank, but provides also a Graph API that eases the implementation of custom graph algorithms.
其他Flink文章请查看:



相关推荐
flink学习资料ppt,应用案列介绍。flink的流式处理的是真正的流处理。流式数据一但进入就实时进行处理,这就允许流数据灵活地在操作窗口。它甚至可以在使用水印的流数中处理数据(It is even capable of handling ...
统计维基百科实时编辑情况的Flink应用,在Flink1.7环境上正常运行
Flink从入门到放弃(入门篇2)-本地环境搭建&构建第一个Flink应用.md
Flink在阿里巴巴电商业务中的应用.pdf
Flink应用案例参考手册-附件资源
今天我们就主要来了解下Flink应用场景分析。 Flink的提出,本身就是针对于实时流计算的,因为之前的无论是Hadoop框架还是Spark框架,都不能算是真正意义上的实时流计算处理引擎,只有Flink,实现了毫秒级低延迟的...
flink开发环境的搭建和应用的配置部署及运行 详细, 阿里巴巴
Flink技术栈及其适用场景.pdf 这里介绍了flink组建的技术栈和使用场景,适合给使用Flink的同学进一步熟悉Flink
1. 2 Flink 应用场景........................................................................................................................................... - 3 - 1.2.1 事件驱动应用程序................
运行首个Flink 应用 .20 小结 .23 第2 章 流处理基础 . 25 Dataflow 编程概述 25 Dataflow 图 25 数据并行和任务并行 26 数据交换策略 .27 并行流处理 28 延迟和吞吐.28 数据流上的操作 .31 时间语义 .36 流处理场景...
flink基本概念与部署,DataStreamAPI,Druid数据存储,Druid基本概念。Flink应用案例教程,Flink状态管理与恢复及容错设计与指标设计。
Flinkk8soperator FlinkK8sOperator是,用于管理Kubernetes上的应用程序。 操作员充当控制平面来管理应用程序的... Flink运营商旨在从应用程序开发人员中抽象出托管,配置,管理和操作Flink集群的复杂性。 它通过使
而当下FlinkSQL的火热程度不用多说,FlinkSQL也为HBase提供了connector,因此HBase与FlinkSQL的结合非常有必要实践实践。当然,本文假设用户有一定的HBase知识基础,不会详细去介绍HBase的架构和原理,本文着重介绍...
附件:Flink-on-yarn部署指南 0、Flink基本原理与生产实践 1、Flink基本概念与部署 2、DataStreamAPI介绍与实战 ...7、Flink应用案例介绍 8、Druid基本概念以及架构设计 9、Druid数据存储与写入 10、Druid实践介绍
flink-jobs为基于Flink的Java应用程序提供快速集成的能力,可通过继承FlinkJobsRunner快速构建基于Java的Flink流批一体应用程序,实现异构数据库实时同步和ETL。flink-jobs提供了数据源管理模块,通过flink-jobs运行...
此案例使用的是IDEA开发工具,项目...使用JavaAPI操作Flink的流处理,Flink从Kafka中获取数据,执行处理后再执行输出。 根据(《Flink入门与实战》徐葳著)教材最后的综合案例改变,适合没有学习不会使用Flume的人使用
Flink在平安银行的应用与实践.pdf
在Scala,Java或Python中构建Flink应用程序以在Flink集群上运行 当前支持的版本: 用于Hadoop 3.2和Scala 2.11的Flink 1.12.2 适用于Hadoop 2.8和Scala 2.11的Flink 1.7.2 适用于Hadoop 2.7和Scala 2.11的Flink ...
Flink架构原理、Flink应用场景、Flink特点优势、Flink分布式集群企业级部署、Flink任务提交、高可用、并行度设置及参数配置、常用API、Flink窗口、Flink状态、FlinkTable、FlinkSQL、Flink复杂时间等一系列Flink热点...